计算机基础复习

一、计算机网络
1. TCP/IP模型和OSI模型
TCP/IP 模型和 OSI 模型是计算机网络中两个重要的参考模型,它们分别定义了网络通信的不同层次和功能。TCP/IP 模型更加实用,更加广泛地应用于实际的网络中。
TCP/IP 模型是一个四层模型,包括应用层、传输层、网络层和链路层。各层的主要功能如下:
- 应用层:提供各种网络应用,如 HTTP、FTP、SMTP 等。
- 传输层:提供端到端的数据传输,包括 TCP(传输控制协议)和 UDP(用户数据报协议)。TCP 提供可靠的、面向连接的通信,而 UDP 提供无连接的通信。
- 网络层:负责数据包的路由和转发,通过 IP 协议实现。
- 网络接口层:为网络层提供链路级别传输的服务,负责在以太网、WiFi这样的底层网络上发送原始数据包,工作在网卡这个层次,使用 MAC 地址来标识网络上的设备。
2. 从输入URL到页面展示发生了什么
- 浏览器对
URL进行解析,从而生成发送给Web服务器的请求信息。 - 然后会通过DNS,查询服务器域名对应的 IP 地址。通过 DNS 获取到 IP 后,就可以把 HTTP 的传输工作交给操作系统中的协议栈。
- 浏览器通过调用 Socket 库,来委托协议栈工作。协议栈的上半部分有两块,分别是负责收发数据的 TCP 和 UDP 协议,这两个传输协议会接受应用层的委托执行收发数据的操作。协议栈的下面一半是用 IP 协议控制网络包收发操作,在互联网上传数据时,数据会被切分成一块块的网络包,而将网络包发送给对方的操作就是由 IP 负责的。此外 IP 中还包括
ICMP协议和ARP协议。ICMP用于告知网络包传送过程中产生的错误以及各种控制信息。ARP用于根据 IP 地址查询相应的以太网 MAC 地址。 - 最后网卡会将数字信息转换为电信号,通过网线发送出去。
- 首先到达交换机,之后到达了路由器,并在此被转发到下一个路由器或目标设备。
- 数据包抵达服务器后,服务器逐层解析,之后将请求的内容在封装成 HTTP 响应报文再返回给客户端。
- 客户端接受到内容之后,逐层解析,最终讲内容显示在浏览器上。
- 最后,客户端向服务器发起了 TCP 四次挥手,至此双方的连接就断开了。
3. HTTP请求
HTTP请求报文和响应报文是怎样的
- HTTP GET请求报文
1 | GET /index.html |
- HTTP POST请求报文
1 | POST /submit-form |
- HTTP 响应报文
1 | 200 OK |
HTTP请求方式有哪些
- GET:请求指定的资源。一般用于请求数据。
- POST:向指定资源提交数据进行处理。一般用于提交表单数据。
- PUT:上传文件或更新资源。
- DELETE:删除指定的资源。
- HEAD:获取资源的头部信息。
- OPTIONS:获取服务器支持的请求方法。
- PATCH:对资源进行部分修改。
GET请求和POST请求的区别
GET 的语义是请求获取指定资源。GET方法是安全、幂等、可被缓存的。
POST 的语义是根据请求负荷(报文主体)对指定的资源做出处理,具体的处理方式视资源类型而不同。POST不安全,不幂等,(大部分实现)不可缓存。
HTTP请求中常见的状态码

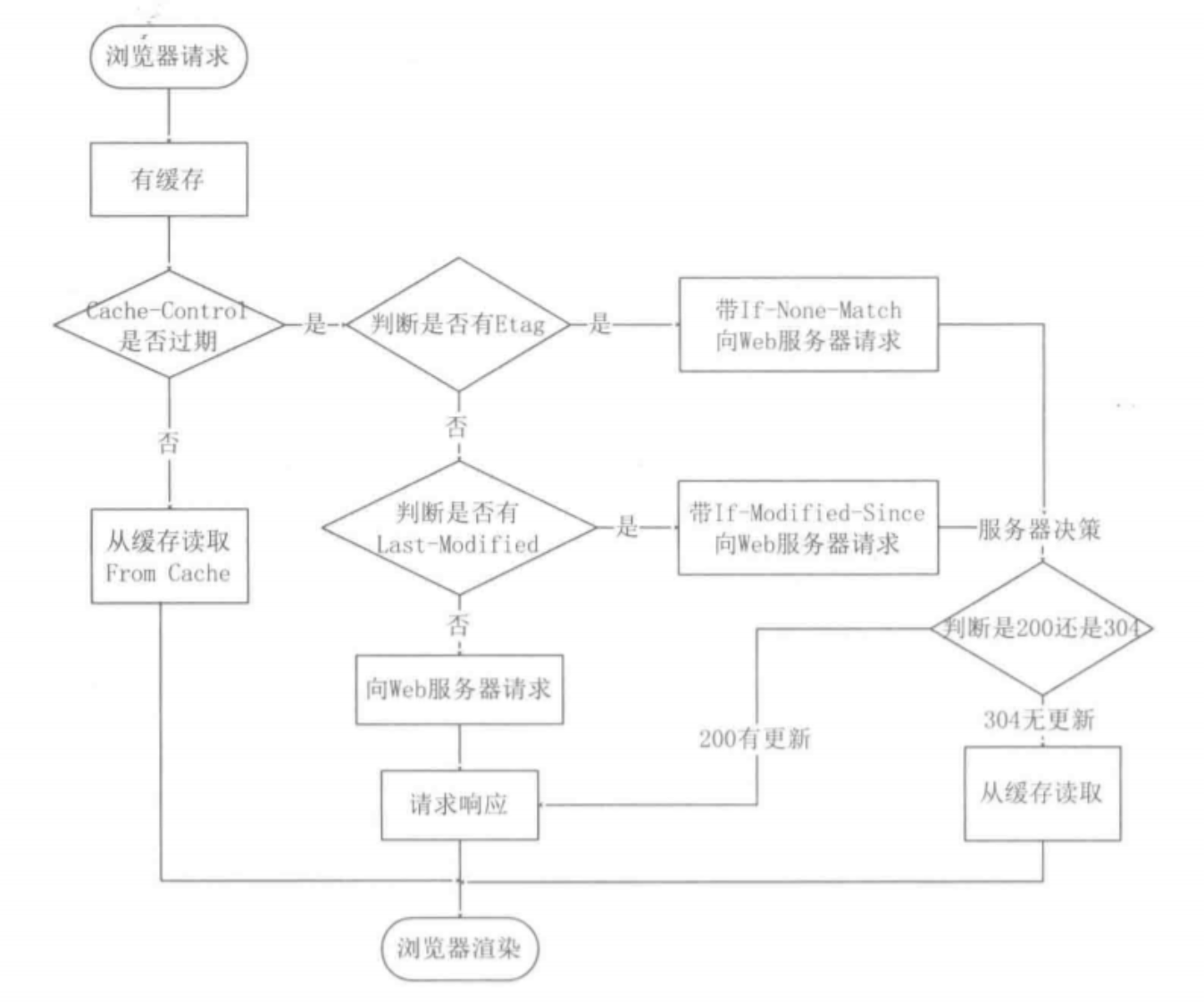
4. 什么是强缓存和协商缓存
- 强缓存指的是只要浏览器判断缓存没有过期,则直接使用浏览器的本地缓存,决定是否使用缓存的主动性在于浏览器这边。
- 协商缓存就是与服务端协商之后,通过协商结果来判断是否使用本地缓存。

5. HTTP
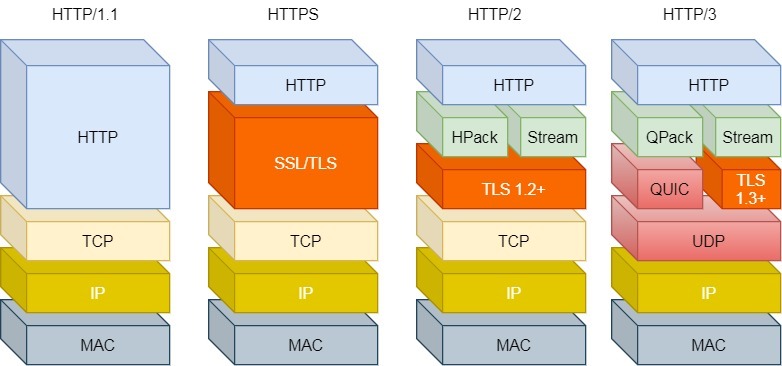
HTTP/1.0 和 HTTP/1.1 的区别
- 连接方式:
- HTTP/1.0 采用短连接,每次请求都需要建立新的连接,请求完成后立即断开连接,这会造成较大的性能开销。
- HTTP/1.1 使用长连接,减少了建立和断开连接的次数,提高了性能。
- 管道传输:
- HTTP/1.1 支持管道(pipeline)网络传输,在第一个请求发出去后不必等待其响应回来就可以发送第二个请求,减少了整体的响应时间。
HTTP/2.0 与 HTTP/1.1 的区别
- 头部压缩:HTTP/2.0 对头部进行压缩,减少了传输的数据量。
- 二进制格式:采用二进制格式传输数据,而不是 HTTP/1.1 的文本格式,提高了传输效率。
- 并发传输:可以同时发送多个请求和响应,提高了并发性能。
- 服务器主动推送资源:服务器可以主动向客户端推送资源,减少了客户端的请求次数。
HTTP/3.0(基于 QUIC 协议)
- 解决队头阻塞问题:
- HTTP/2 的队头阻塞问题是因为使用 TCP 协议,HTTP/3 将下层的 TCP 协议改成 UDP 协议。
- UDP 发送数据不管顺序也不管丢包,但基于 UDP 的 QUIC 协议可以实现类似 TCP 的可靠性传输。
- QUIC 协议的特点:
- 无队头阻塞:避免了因一个数据包丢失而阻塞后续数据包的情况。
- 更快的连接建立:相比传统的 TCP 连接建立过程更快。
- 连接迁移:可以在不同的网络环境下保持连接的稳定性,例如在移动网络切换时。
6. HTTPS
HTTP和HTTPS有哪些区别
HTTPS(Hypertext Transfer Protocol Secure)即超文本传输安全协议,是在HTTP的基础上通过传输加密和身份认证保证了传输过程的安全性。
- HTTP 是超文本传输协议,信息是明文传输,存在安全风险的问题。HTTPS 则解决 HTTP 不安全的缺陷,在 TCP 和 HTTP 网络层之间加入了 SSL/TLS 安全协议,使得报文能够加密传输。
- HTTP 连接建立相对简单, TCP 三次握手之后便可进行 HTTP 的报文传输。而 HTTPS 在 TCP 三次握手之后,还需进行 SSL/TLS 的握手过程,才可进入加密报文传输。
- 两者的默认端口不一样,HTTP 默认端口号是 80,HTTPS 默认端口号是 443。
- HTTPS 协议需要向 CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的。
HTTPS工作原理
一、基本概念
- 对称加密:通信双方使用相同的密钥进行加密和解密。这种方式的优点是加密和解密速度快,但密钥的分发存在安全风险。例如,双方使用密钥“abc123”对数据进行加密和解密,如果有人在密钥分发过程中窃取了这个密钥,就可以解密通信内容。
- 非对称加密:使用一对密钥,即公钥和私钥。公钥可以公开,用于加密数据;私钥由所有者保密,用于解密数据。例如,A 要给 B 发送消息,A 用 B 的公钥加密消息,B 收到后用自己的私钥解密。这种方式解决了密钥分发的问题,但加密和解密速度相对较慢。
- 数字证书:由权威机构颁发,用于证明公钥所有者的身份。数字证书包含公钥、所有者信息、颁发机构信息等,并且经过数字签名,确保其真实性和完整性。例如,当你访问一个银行网站时,浏览器会检查该网站的数字证书,以确保证书是由受信任的机构颁发,并且证书中的公钥确实属于该银行。
二、工作流程
-
客户端发起请求:
- 客户端(通常是浏览器)向服务器发起 HTTPS 请求,请求中包含支持的加密算法列表等信息。例如,客户端可能支持 AES、RSA 等加密算法,并将这些信息告知服务器。
- 客户端生成一个随机数(称为客户端随机数),用于后续的密钥生成。
-
服务器响应:
- 服务器收到请求后,选择一种客户端支持的加密算法,并返回自己的数字证书给客户端。
- 服务器也生成一个随机数(称为服务器随机数)。
-
客户端验证证书:
- 客户端收到服务器的数字证书后,验证证书的合法性。这包括检查证书的颁发机构是否受信任、证书是否过期、证书中的域名是否与访问的域名一致等。
- 如果证书验证通过,客户端从证书中提取服务器的公钥。
-
生成会话密钥:
- 客户端使用服务器的公钥加密客户端随机数,并发送给服务器。
- 服务器使用私钥解密收到的客户端随机数。
- 此时,客户端和服务器都拥有了客户端随机数和服务器随机数。双方使用这两个随机数和预先确定的加密算法,生成一个会话密钥,用于后续的通信加密和解密。
-
加密通信:
- 客户端使用会话密钥对要发送的数据进行加密,并发送给服务器。
- 服务器使用会话密钥解密收到的数据。
- 同样,服务器使用会话密钥对要返回的数据进行加密,并发送给客户端。
- 客户端使用会话密钥解密收到的数据。
三、总结
HTTPS 通过非对称加密解决了密钥分发的问题,通过对称加密保证了通信的效率,同时使用数字证书确保了通信双方的身份真实性。这样,在网络通信中,即使数据被窃取,攻击者也很难解密通信内容,从而保证了通信的安全性。
- 混合加密的方式实现信息的机密性,解决了窃听的风险。
- 摘要算法的方式来实现完整性,它能够为数据生成独一无二的指纹,指纹用于校验数据的完整性,解决了篡改的风险。
- 将服务器公钥放入到数字证书中,解决了冒充的风险。
7. TCP和UDP
区别
-
TCP 是面向连接的传输层协议,传输数据前先要建立连接。
-
UDP 是不需要连接,即刻传输数据。
-
TCP 是一对一的两点服务,即一条连接只有两个端点。
-
UDP 支持一对一、一对多、多对多的交互通信
-
TCP 是可靠交付数据的,数据可以无差错、不丢失、不重复、按序到达。
-
UDP 是尽最大努力交付,不保证可靠交付数据。但是可以基于 UDP 传输协议实现一个可靠的传输协议,比如 QUIC 协议
-
TCP 有拥塞控制和流量控制机制,保证数据传输的安全性。
-
UDP 没有,即使网络非常拥堵了,也不会影响 UDP 的发送速率。
-
TCP 是流式传输,没有边界,但保证顺序和可靠。
-
UDP 是一个包一个包的发送,是有边界的,但可能会丢包和乱序。
TCP连接如何保证可靠性
TCP(Transmission Control Protocol)通过以下机制保证连接的可靠性:
- 三次握手:建立连接前进行三次握手,确保连接双方准备就绪,并同步初始序列号。
- 确认应答(ACK):接收方收到数据后发送确认信息(ACK)给发送方,确保数据成功接收。
- 重传机制:发送方在超时未收到ACK时,会重传未确认的数据包,确保数据传输成功。
- 序列号和校验和:每个数据包都有唯一的序列号,接收方可以按序组装数据。校验和用于检测数据包是否被损坏。
- 流量控制和拥塞控制:通过滑动窗口和拥塞控制算法(如慢启动、拥塞避免等)调节数据传输速率,防止网络拥塞和数据丢失。
UDP怎么实现可靠传输
UDP(User Datagram Protocol)本身是一个不可靠的传输协议,没有内置的可靠性机制,如确认、重传、流量控制等。然而,可以通过在应用层加入一些额外的机制来实现可靠传输。常用的方式包括:
- 确认机制(ACK):接收方在接收到数据后发送确认信息(ACK)给发送方,发送方在未收到确认信息时重发数据包。
- 超时重传:发送方在发送数据包后启动定时器,如果在一定时间内未收到确认信息,则重新发送数据包。
- 序列号:在数据包中添加序列号,接收方可以根据序列号来检测是否有数据包丢失或重复,保证数据包按序接收。
- 滑动窗口:可以借鉴TCP的滑动窗口机制,实现流量控制和有序的数据传输。
8. 三次握手的过程,为什么是三次
三次握手过程:
- 第一次握手:客户端发送一个SYN(同步)报文给服务器,表示请求建立连接,同时携带初始序列号(SYN=1, Seq=x)。
- 第二次握手:服务器收到SYN后,回复SYN和ACK(确认),表示同意连接,并发送自己的初始序列号(SYN=1, ACK=x+1, Seq=y)。
- 第三次握手:客户端收到SYN-ACK后,再发送一个ACK报文确认(ACK=y+1),连接建立。
为什么是三次:
三次握手的目的是为了确保双方的接收和发送能力都正常。通过三次握手,客户端和服务器可以相互确认对方的接收和发送能力。具体来说:
- 第一次握手:客户端确认自己发送正常。
- 第二次握手:服务器确认客户端发送正常,自己接收和发送正常。
- 第三次握手:客户端确认服务器的接收和发送能力都正常。
9.四次挥手的过程,为什么是四次
四次挥手过程:
- 第一次挥手:客户端发送FIN报文,表示不再发送数据,但还可以接收数据(FIN=1, Seq=x)。
- 第二次挥手:服务器收到FIN后,回复ACK报文,表示确认(ACK=x+1),此时服务器可能还有未发送的数据。
- 第三次挥手:服务器数据发送完毕后,发送FIN报文,表示不再发送数据(FIN=1, Seq=y)。
- 第四次挥手:客户端收到FIN后,发送ACK报文确认(ACK=y+1),连接正式关闭。
为什么是四次:
TCP是全双工通信协议,双方通信需要分别关闭。四次挥手中,客户端和服务器分别发送FIN和ACK来关闭各自的连接,因此需要四次交互来确保双方的数据传输彻底结束。
10. HTTP的Keep-Alive是什么?TCP的和HTTP的相同吗?
HTTP Keep-Alive:
HTTP Keep-Alive是一种机制,允许在同一个TCP连接上发送多个HTTP请求和响应,而不必为每个请求重新建立TCP连接。这样可以减少连接建立和关闭的开销,提高传输效率。
TCP Keep-Alive:
TCP Keep-Alive是TCP层的一个选项,用于检测长时间空闲的连接是否仍然存活。它会周期性地发送探测报文,如果一段时间没有响应,连接将被视为断开。
区别:
- HTTP Keep-Alive:关注的是HTTP协议层的多次请求复用,减少TCP连接的频繁创建和销毁。
- TCP Keep-Alive:关注的是TCP连接的存活性,防止因长时间无数据传输导致连接断开。
11. DNS查询过程
DNS(Domain Name System)查询的过程一般包括以下步骤:
- 浏览器缓存查询:首先查询本地浏览器缓存是否有对应的DNS记录。
- 操作系统缓存查询:若浏览器缓存没有,操作系统会查询本地的DNS缓存。
- 本地域名服务器查询:若本地缓存未命中,操作系统会向配置的DNS服务器(本地域名服务器)发送查询请求。
- 递归查询:如果本地域名服务器未命中,它会以递归方式向根域名服务器发起查询请求,根服务器会指引到顶级域(如.com)的服务器。
- 权威域名服务器查询:经过顶级域名服务器的指引,最终查询到权威域名服务器,获取到目标IP地址。
- 返回结果:查询结果逐级返回到客户端,完成域名解析。
12. CDN是什么
CDN(Content Delivery Network)是内容分发网络,目的是加速互联网内容的分发。它通过将内容缓存到多个地理位置分散的服务器节点上,使用户可以从离自己最近的节点获取内容,从而减少网络延迟,提升访问速度。
13. Cookie和Session是什么?有什么区别?
-
Cookie:Cookie是存储在客户端的一小段数据,通常由服务器生成,并由客户端在每次请求时携带发送。Cookie可以用于身份验证、会话跟踪等。
-
Session:Session是服务器端保存用户状态的机制,通常用于存储用户登录状态、购物车信息等。每个Session都有一个唯一的ID,客户端通过Cookie或URL参数将这个ID传递给服务器。
区别:
- 存储位置:Cookie存储在客户端,Session存储在服务器端。
- 安全性:Session更安全,数据存储在服务器上,不易被篡改;而Cookie存储在客户端,可能被窃取或篡改。
- 生命周期:Cookie可以设置过期时间,长期存储在客户端;Session一般在用户关闭浏览器或超时后失效。
- 存储大小:Cookie有存储大小限制(一般为4KB),而Session可以存储更多数据,因为它在服务器上。
二、操作系统
1. 进程和线程的区别
(1) 定义方面
- 进程:是资源分配的基本单位,拥有独立的内存空间,包括代码、数据、堆、栈等。
- 线程:是程序执行的最小单位,是进程中的一个执行路径,多个线程共享进程的内存空间和资源。
(2) 资源占用
- 进程:启动一个进程需要分配较多的系统资源,如内存空间、文件描述符等。
- 线程:创建和切换线程比进程更加轻量级,占用的资源相对较少。
(3) 并发性
- 进程:进程之间的并发性较低,因为切换进程需要进行较多的系统操作。
- 线程:线程之间的切换速度较快,可以实现更高的并发性。
(4) 通信方式
- 进程:进程间通信相对复杂,可以通过管道、消息队列、共享内存等方式进行通信。
- 线程:线程间通信比较简单,可以直接通过共享内存进行通信。
(5) 稳定性
- 进程:一个进程出现问题通常不会影响其他进程。
- 线程:一个线程出现问题可能会导致整个进程崩溃。
2. 并行和并发有什么区别
- 并行是指在同一时刻,多个任务同时在不同的硬件资源上执行。
- 并发是指在同一时间段内,多个任务都在推进,但并非一定在同一时刻同时执行。这些任务可能交替执行,也可能在一段时间内重叠执行。
3. 解释一下用户态和核心态
用户态(User Mode)
用户态是指应用程序运行的模式。在用户态下,程序只能执行受限的一组指令,并且不能直接访问硬件资源和敏感数据。这种限制是为了保护系统的稳定性和安全性,防止应用程序意外或恶意地影响其他程序或操作系统本身。
- 权限低:只能访问有限的系统资源。
- 受保护:不能直接与硬件交互,必须通过系统调用(System Call)请求操作系统来完成硬件访问。
- 安全性高:由于权限受限,应用程序无法直接操作敏感资源,减少了系统崩溃或数据损坏的风险。
在操作系统中,用户态程序(如文字处理软件、网页浏览器等)通过系统调用向操作系统请求服务,例如读取文件、发送网络数据等。比如,当一个文字处理软件需要打开一个文件时,它会通过系统调用请求操作系统打开文件并读取其内容。
核心态(Kernel Mode)
核心态是指操作系统内核运行的模式。在核心态下,操作系统具有最高的权限,可以执行所有指令并访问所有资源,包括硬件设备、内存和外设。
- 权限高:可以执行所有CPU指令并访问所有系统资源。
- 直接访问:可以直接与硬件交互,执行关键的系统操作。
- 潜在风险:如果在核心态下执行的代码出现错误,可能会导致系统崩溃或严重故障。
操作系统内核在处理硬件中断、内存管理、任务调度等关键操作时会运行在核心态。例如,当操作系统接收到一个硬件中断信号(比如键盘输入),内核会切换到核心态来处理该中断信号,并完成相应的操作。
4. 进程通信算法你了解多少
进程通信算法用于在多个进程之间交换信息。常见的进程通信算法包括:
- 消息传递机制:进程之间通过消息队列、信号量、管道等机制传递消息。典型的消息传递算法包括同步和异步消息传递,其中同步消息传递要求发送方和接收方都准备好才能传递消息,而异步消息传递则可以允许消息存储在缓冲区中,等待接收方处理。
- 共享内存机制:多个进程共享同一块内存区域,通过读取和写入共享内存实现通信。为了保证数据一致性,常常需要使用同步机制如信号量或互斥锁。
- 生产者-消费者问题:这是经典的进程通信问题,其中生产者进程生成数据并放入缓冲区,消费者进程从缓冲区读取数据。常见算法包括使用信号量或条件变量来协调生产者和消费者的操作。
5. 进程间有哪些通信方式
常见的进程间通信方式包括:
- 管道(Pipe):管道是单向的通信通道,通常用于具有亲缘关系的进程之间进行通信,如父子进程。
- 命名管道(FIFO):命名管道是双向的,可以在无亲缘关系的进程之间通信。
- 消息队列:消息队列是一种基于消息的通信机制,允许进程以消息的形式发送和接收数据,支持异步通信。
- 共享内存:共享内存允许多个进程共享一块内存区域,提供最快的通信方式,但需要同步机制确保数据一致性。
- 信号量:信号量用于控制对共享资源的访问,常用于进程同步和互斥。
- 套接字(Socket):套接字通常用于网络通信,但也可以用于同一台主机上的进程之间通信。
- 信号(Signal):信号是一种异步的通信机制,进程可以通过信号通知另一个进程发生了某些事件。
6. 解释一下进程同步和互斥,以及如何实现进程同步和互斥
-
进程同步:进程同步是指多个进程在某些操作上需要协调执行,以确保操作的正确性。例如,生产者-消费者问题中的同步要求生产者必须在缓冲区未满时生产,消费者必须在缓冲区非空时消费。
-
进程互斥:进程互斥是指多个进程不能同时访问某些共享资源。例如,多个进程不能同时向同一个文件写入数据,以避免数据不一致。
实现方式:
- 信号量(Semaphore):信号量是一个计数器,用于控制多个进程对共享资源的访问。二进制信号量可以实现互斥,计数信号量可以实现同步。
- 互斥锁(Mutex):互斥锁用于确保只有一个进程能够访问共享资源,适用于进程互斥。
- 条件变量:条件变量允许进程在满足特定条件时进行等待或通知,常与互斥锁配合使用,实现进程同步。
- 自旋锁(Spinlock):自旋锁是一种忙等待锁,进程在获取锁之前不断检查锁的状态,适用于短时间的互斥。
7. 什么是死锁,如何预防死锁?
死锁:死锁是一种进程阻塞的现象,多个进程互相等待对方释放资源,导致系统进入无法推进的状态。
死锁的四个必要条件:
- 互斥:某些资源只能被一个进程独占。
- 占有并等待:进程已经占有至少一个资源,同时又在等待其他资源。
- 不可剥夺:资源不能被强制剥夺,只能由占有它的进程主动释放。
- 循环等待:存在一个进程链,进程间相互等待,形成循环。
预防死锁的方法:
- 资源分配预防:确保系统不进入可能导致死锁的状态。例如,银行家算法通过资源分配策略避免系统进入死锁状态。
- 死锁避免:在资源分配时,动态检查资源分配的安全性,避免产生死锁。
- 死锁检测与恢复:允许系统进入死锁状态,但通过检测机制识别并终止死锁进程或回收资源。
- 破坏必要条件:通过破坏死锁的四个必要条件之一来防止死锁的发生。例如,通过资源可剥夺或通过一次性分配所有资源来避免死锁。
8. 介绍一下几种调度算法的特征
- 先来先服务(FCFS, First-Come, First-Served):
- 特点:按进程到达的顺序进行调度,简单但可能导致较长的平均等待时间(如出现长作业时)。
- 缺点:容易引发“长作业阻塞短作业”的问题,导致不公平。
- 短作业优先(SJF, Shortest Job First):
- 特点:优先调度运行时间最短的作业,平均等待时间最小。
- 缺点:需要预知作业长度,可能导致“饥饿”现象(长作业长期得不到调度)。
- 优先级调度(Priority Scheduling):
- 特点:根据优先级进行调度,优先级高的进程优先执行。
- 缺点:低优先级的进程可能一直得不到执行,导致饥饿问题。
- 时间片轮转(RR, Round Robin):
- 特点:每个进程分配一个固定的时间片,轮流执行,适用于时间共享系统。
- 优点:公平性好,响应时间较短。
- 缺点:时间片设置不当可能导致频繁切换或响应时间过长。
- 多级反馈队列(Multilevel Feedback Queue):
- 特点:将进程按优先级分为多个队列,队列内的进程按不同的调度策略执行,短作业优先,长作业会被降低优先级。
- 优点:灵活性高,兼顾了响应时间和公平性。
9. 讲一讲你理解的虚拟内存
虚拟内存是计算机系统的一种内存管理技术,它允许程序在比实际物理内存更大的地址空间中运行。虚拟内存通过将程序的地址空间划分为页(或段),并按需将这些页加载到物理内存中,从而实现“部分加载”程序的功能。
虚拟内存的主要功能:
- 扩展内存空间:虚拟内存通过使用硬盘来扩展物理内存,使得程序可以使用比物理内存更大的地址空间。
- 进程隔离:每个进程拥有独立的虚拟地址空间,避免进程之间直接访问彼此的内存。
- 按需调页:当进程访问未在物理内存中的页时,操作系统会产生缺页中断,并从硬盘中将所需的页调入内存。
10. 你知道的线程同步的方式有哪些?
线程同步的常用方式包括:
- 互斥锁(Mutex):用于确保同一时刻只有一个线程可以访问共享资源。
- 信号量(Semaphore):用于控制多个线程对共享资源的访问,允许同时多个线程进入临界区。
- 条件变量(Condition Variable):用于线程等待某个条件成立,常与互斥锁结合使用。
- 读写锁(Read-Write Lock):允许多个线程同时读数据,但只允许一个线程写数据,适合读多写少的场景。
- 自旋锁(Spinlock):一种忙等待锁,适用于短时间锁定的场景。
11. 有哪些页面置换算法
常见的页面置换算法有:
- 先进先出(FIFO, First-In-First-Out):最早进入内存的页最先被替换,简单但性能较差,容易发生“Belady异常”。
- 最少使用(LRU, Least Recently Used):替换最近最少使用的页面,性能较好但实现复杂。
- 最佳(Optimal):选择未来最久不会使用的页面进行替换,理论最优但无法实际实现。
- 时钟算法(Clock Algorithm):对FIFO的改进,使用一个指针循环遍历页表,通过访问位判断是否需要替
12. 熟悉哪些Linux命令
cp:复制文件或目录。cp source destination:复制文件。cp -r source_directory destination_directory:递归复制目录。
mv:移动或重命名文件或目录。mv old_name new_name:重命名文件。mv file_name directory/:将文件移动到指定目录。
rm:删除文件或目录。rm file_name:删除文件。rm -r directory_name:递归删除目录。
mkdir:创建新目录。mkdir directory_name:创建一个新目录。mkdir -p parent_directory/sub_directory:递归创建目录。
ps:显示当前运行的进程。ps aux:显示所有进程的详细信息。ps -ef:另一种显示进程详细信息的方式。
top:实时显示系统进程。h/btop:是top的增强版,需要单独安装。
chmod:改变文件或目录的权限。chmod 755 file_name:设置权限。
chown:改变文件或目录的所有者。chown user:group file_name:更改文件所有者和组。
grep:在文件中搜索文本。grep 'pattern' file_name:搜索文件中匹配的行。
find:查找文件或目录。find /path -name "file_name":按名称查找文件。
13. 如何查看某个端口有没有被占用
使用 netstat 命令:netstat -tuln | grep :8080
14. 说一下 select、poll、epoll
select、poll 和 epoll 是 Linux 系统中用于实现 I/O 多路复用的系统调用,它们用于监视多个文件描述符(通常是套接字)以便检测哪些描述符有 I/O 事件需要处理(例如,读、写或异常)。这些机制在高并发服务器编程中非常重要。
1. select
-
特点:
select是最早的 I/O 多路复用机制,它通过一个文件描述符集合来监视多个文件描述符的状态。- 使用时,开发者需要将要监控的文件描述符加入
fd_set集合,并通过select()函数来监视这些描述符的状态变化。 select的每次调用都需要重新设置文件描述符集合,且它有文件描述符数量的限制,通常为 1024。
-
缺点:
- 每次调用
select都需要将文件描述符集合从用户态复制到内核态,开销较大。 select的文件描述符数量受限制(一般是 1024),在处理大量文件描述符时效率较低。- 返回时需要遍历整个文件描述符集合,确定哪些描述符发生了事件,性能不佳。
- 每次调用
2. poll
-
特点:
poll是select的改进版本,它去除了文件描述符数量的限制,能够监视任意数量的文件描述符。poll使用一个pollfd数组,数组中的每个元素代表一个文件描述符及其感兴趣的事件。- 调用
poll()时,开发者传递这个数组给内核,内核在事件发生时更新数组中的事件状态。
-
优点:
- 解决了
select的文件描述符数量限制问题。 poll可以处理任意数量的文件描述符,适用于较大的并发量。
- 解决了
-
缺点:
- 和
select类似,poll也需要将文件描述符列表从用户态传递到内核态,每次调用都要重新传递。 - 事件发生后需要遍历整个文件描述符数组来找到就绪的描述符,因此在大量描述符的情况下效率依然较低。
- 和
3. epoll
-
特点:
epoll是 Linux 特有的 I/O 多路复用机制,它对select和poll进行了大幅优化,特别适合处理大量并发连接的场景。epoll使用事件通知机制,通过一个epoll实例来管理多个文件描述符的事件,事件的注册和监听是通过epoll_ctl函数来完成的。- 与
select和poll不同,epoll采用了事件驱动模式,当有事件发生时,内核会主动通知,不需要每次都重新传递整个文件描述符集合。
-
优点:
- 高效:
epoll只会返回有事件发生的文件描述符,而不需要遍历整个文件描述符集合,性能更高。 - 无文件描述符限制:
epoll没有文件描述符数量的限制,适合大规模并发场景。 - 支持水平触发(LT)和边缘触发(ET):其中 ET 模式能够进一步减少重复的事件通知,提高性能。
- 高效:
-
缺点:
- 仅在 Linux 上支持,跨平台性较差。
总结对比
- select:简单但效率低,文件描述符有数量限制,适用于小规模的并发场景。
- poll:移除了文件描述符数量限制,但依然存在每次调用都需要传递文件描述符数组的问题,适合中等规模并发场景。
- epoll:高效、无文件描述符限制,特别适合大规模并发场景,是目前 Linux 下性能最好的 I/O 多路复用机制。
epoll是解决lc10k问题的利器,通过两个方面解决了select/poll的问题。
-
epoll 在内核里使用红黑树来关注进程所有待检测的 socket,红黑树是个高效的数据结构,增删改一般时间复杂度是
,通过对这棵黑红树的管理,不需要像 select/poll在每次操作时都传入整个socket集合,减少了内核和用户空间大量的数据拷贝和内存分配。 -
epoll 使用事件驱动的机制,内核里维护了一个链表来记录就绪事件,只将有事件发生的socket 集合传递给应用程序,不需要像 select/poll 那样轮询扫描整个集合(包含有和无事件的 socket ),大大提高了检测的效率。
而且,epoll 支持边缘触发和水平触发的方式,而 select/poll 只支持水平触发,一般而言,边缘触发的方式会比水平触发的效率高。
epoll 通常是高性能服务器编程的首选。
三、数据库
1. 一条SQL查询语句是如何执行的?
- 连接器:建立连接,管理连接、校验用户身份;
- 查询缓存:查询语句如果命中查询缓存则直接返回,否则继续往下执行。MySQL 8.0 已删除该模块;
- 解析 SQL,通过解析器对 SQL 查询语句进行词法分析、语法分析,然后构建语法树,方便后续模块读取表名、字段、语句类型;
- 执行 SQL:
- 预处理阶段:检查表或字段是否存在;将 select * 中的 * 符号扩展为表上的所有列。
- 优化阶段:基于查询成本的考虑,选择查询成本最小的执行计划;
- 执行阶段:根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端;
2. 数据库的事务隔离级别有哪些?
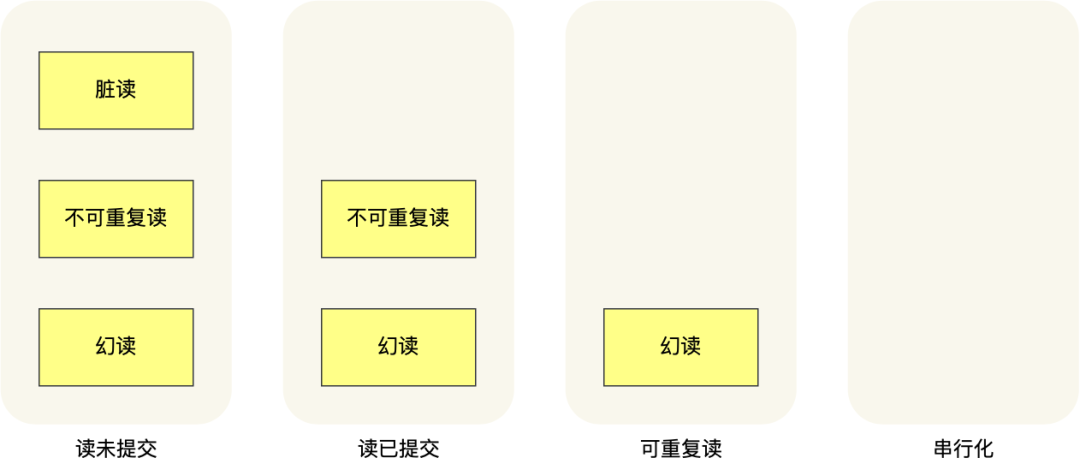
SQL 标准定义了四种事务隔离级别,它们决定了事务之间相互影响的程度:
- 读未提交(Read Uncommitted):一个事务可以读取到其他事务未提交的数据,可能会导致“脏读”问题。
- 读已提交(Read Committed):一个事务只能读取到其他事务已经提交的数据,避免了脏读,但仍然可能发生不可重复读。
- 可重复读(Repeatable Read):确保在同一个事务中,多次读取同样的数据结果是一致的,避免不可重复读。MySQL InnoDB 引擎的默认隔离级别。
- 可串行化(Serializable):最严格的隔离级别,将事务完全串行化执行,避免了幻读、不可重复读等问题,但性能最差。
- 脏读:读到其他事务未提交的数据;
- 不可重复读:前后读取的数据不一致;
- 幻读:前后读取的记录数量不一致。
3. 事务的四大特性有哪些?
事务的四大特性(ACID)包括:
- 原子性(Atomicity):事务中的操作要么全部成功,要么全部回滚,保证事务不可分割。
- 一致性(Consistency):事务执行前后,数据库的状态应保持一致,不会破坏数据的完整性。
- 隔离性(Isolation):一个事务的执行不会受到其他事务的干扰,多个事务并发执行时相互隔离。
- 持久性(Durability):事务提交后,其对数据库的修改是永久的,即使系统发生故障,数据也不会丢失。
4. MySQL的执行引擎有哪些?
MySQL 支持多种存储引擎,常见的包括:
- InnoDB:默认的存储引擎,支持事务、外键、行级锁,是 MySQL 中使用最广泛的引擎。
- MyISAM:不支持事务和外键,支持表级锁,适合读多写少的场景,查询性能较好。以读为主的应用,如数据仓库、日志分析等。对事务要求不高,且需要快速查询和较少磁盘空间占用的场景。
- Memory:将数据存储在内存中,适用于需要快速访问的数据,断电即丢失数据。
- CSV:数据以 CSV 格式存储,适用于简单的数据存储需求。
- Archive:适合存储归档数据,支持高效的插入操作,但不支持索引。
5. MySQL为什么使用B+树作索引
MySQL 使用 B+ 树作为索引的原因包括:
- 平衡性:B+ 树是一种平衡树,树的高度较低,因此查询速度快,可以在
的时间复杂度内找到数据。 - 顺序访问指针:B+ 树的叶子节点通过链表相连,便于区间查询操作,如范围查找和排序操作。
- 磁盘读写效率高:B+ 树的节点分布均匀,通常一个节点可以包含多个数据块,减少了磁盘 I/O 次数,提高了查询性能。
6. 说一下索引失效的场景?
索引失效的常见场景包括:
- 使用了
OR关键字:当OR语句的条件中存在未加索引的列时,索引可能失效。 - 使用了函数操作:对索引列使用了函数或表达式进行操作(如
SELECT * FROM table WHERE FUNC(column) = value),索引会失效。 - 类型不匹配:当查询条件中的数据类型与索引列的数据类型不一致时,索引可能会失效。
- 前缀匹配:对于组合索引,如果查询条件中没有使用最左边的列,索引会失效(即违反最左前缀原则)。
- 使用了
!=或<>:非等值查询条件可能会导致索引失效。 - 范围查询后再用索引列:在一个索引中,若对某列使用了范围查询(如
BETWEEN或> <),后续列的索引失效。
7. undo log、redo log、binlog 有什么用?
- undo log:记录事务操作的反向操作,用于回滚事务。当事务发生错误或者用户要求回滚时,通过 undo log 恢复到事务执行前的状态。
- redo log:记录已提交事务的修改,用于恢复系统崩溃后的数据一致性。即使数据库宕机,通过 redo log 可以保证已提交的数据不会丢失。
- binlog:二进制日志,记录所有数据库的写操作,用于数据恢复和主从复制。与 redo log 不同,binlog 是逻辑日志,按 SQL 语句的形式记录。
8. 什么是慢查询?原因是什么?可以怎么优化?
慢查询 是指执行时间较长的 SQL 查询,MySQL 会将超过 long_query_time 参数设置时间的查询记录到慢查询日志中。
慢查询原因:
- 缺少索引或使用了不合适的索引。
- 查询的数据量过大,导致表扫描或文件排序。
- 错误的查询方式(如不必要的子查询或联表)。
- 硬件瓶颈,如 I/O 性能不足。
优化方法:
- 添加或优化索引。
- 优化 SQL 语句,避免不必要的全表扫描。
- 分析执行计划,使用
EXPLAIN命令优化查询。 - 使用分区表或分库分表,减少单次查询的数据量。
- 升级硬件,增加内存或优化磁盘 I/O 性能。
9. MySQL和Redis的区别?
- 数据存储位置:MySQL 存储在磁盘中,适合持久化存储;Redis 数据存储在内存中,适合需要快速访问的数据。
- 数据类型:MySQL 是关系型数据库,支持复杂的 SQL 查询;Redis 是 NoSQL 数据库,支持简单的键值对和五种数据结构(如字符串、列表、集合等)。
- 性能:由于 Redis 将数据存储在内存中,查询速度比 MySQL 更快,适合高并发和低延迟的场景。
- 应用场景:MySQL 适合存储重要数据、事务处理和复杂查询;Redis 更适合作为缓存、消息队列或实时数据存储。
10. Redis有什么特点吗?为什么用Redis查询会比较快?
Redis 的主要特点包括:
- 数据存储在内存中:Redis 将数据存储在内存中,读写速度极快,适合高并发、高性能的场景。
- 多种数据类型:Redis 支持丰富的数据类型,包括字符串、列表、集合、哈希表、有序集合等,满足多样化的数据存储需求。
- 支持持久化:虽然 Redis 是内存数据库,但它支持 RDB 和 AOF 两种持久化机制,确保数据不丢失。
- 主从复制和分布式架构:Redis 支持主从复制、哨兵模式和集群模式,方便实现高可用性和扩展性。
- Lua 脚本:Redis 支持在服务端执行 Lua 脚本,减少网络开销。
查询快的原因:
- 内存存储:Redis 将数据存储在内存中,读取速度远快于磁盘存储。
- 单线程模型:Redis 使用单线程模型,避免了多线程带来的上下文切换和锁竞争问题,确保了查询效率。
- 高效的数据结构:Redis 的数据结构经过高度优化,减少了数据操作的时间复杂度。
11. Redis的数据类型有哪些?
Redis 支持五种基本数据类型:
- 字符串(String):可以存储任意类型的字符串数据,包括数字、二进制数据等。
- 列表(List):链表结构,可以快速在两端插入和删除元素。
- 集合(Set):无序集合,自动去重,支持集合运算(如交集、并集)。
- 哈希表(Hash):键值对集合,适合存储对象。
- 有序集合(Sorted Set):带有分数的集合,支持按分数排序。
12. Redis是单线程的还是多线程的,为什么?
Redis 是单线程的。之所以使用单线程,是因为 Redis 的主要瓶颈在于内存访问速度,而不是 CPU 处理能力。通过单线程模型,Redis 可以避免多线程环境下的锁竞争、上下文切换等开销,从而简化了设计,提高了执行效率。Redis 的非阻塞 I/O 模型(基于 epoll)使其在单线程下也能高效地处理高并发请求。
13. Redis持久化机制有哪些
Redis 提供两种持久化机制:
- RDB(Redis Database)快照:定期将内存数据以快照的形式保存到磁盘中,适合数据丢失容忍度较高的场景。RDB 是基于定时保存的,可能会丢失最后一次保存之后的数据。
- AOF(Append Only File)日志:将每一次写操作以日志的形式追加到文件中,支持多种同步策略(如每秒一次、每次写操作或操作系统控制)。AOF 使数据恢复更加安全,但文件体积比 RDB 大。
Redis 允许同时使用 RDB 和 AOF,两者可以互为补充。
14. 缓存雪崩、击穿、穿透和解决办法
-
缓存雪崩:大量缓存同时失效,导致请求直接打到数据库,可能引发数据库崩溃。
- 解决办法:缓存的过期时间设置随机,避免大量缓存同时失效;引入限流机制,防止流量瞬间涌入数据库。
-
缓存击穿:某个热点 key 失效,大量请求直接打到数据库。
- 解决办法:热点数据不过期;使用互斥锁,只有第一个请求去加载数据,其他请求等待。
-
缓存穿透:查询的数据既不在缓存中,也不在数据库中,导致每次请求都要访问数据库。
- 解决办法:将无效请求缓存(如存储为 null 值);使用布隆过滤器拦截无效请求。
15. 如何保证缓存和数据库的一致性
缓存和数据库一致性问题可以通过以下几种方式来保证:
- 先更新数据库,再删除缓存:事务提交后删除缓存,确保缓存和数据库同步更新。缺点是删除缓存操作可能失败,导致脏数据。
- 延迟双删策略:先删除缓存,再更新数据库,最后再延迟删除缓存,确保缓存不会保留旧数据。
- 订阅数据库变更:使用消息队列或数据库的变更订阅功能,当数据库发生变化时,通知缓存层更新数据。
四、C++基础
1. 静态变量和全局变量、局部变量的区别、在内存上怎么分布的
-
全局变量:全局变量的作用域在整个程序中,它可以在任何地方被访问。全局变量存储在内存中的全局数据区(也称为数据段),它的生命周期从程序开始到结束。全局变量在程序的整个运行期间都存在。
-
静态变量:
- 静态局部变量:在函数内部定义的静态局部变量,作用域仅限于该函数,但其生命周期与程序相同,也就是说,即使函数结束,静态局部变量的值也不会丢失。它们也存储在全局数据区。
- 静态全局变量:作用域仅限于定义它的文件中,与普通全局变量相比,静态全局变量不能被其他文件访问。静态全局变量同样存储在全局数据区。
-
局部变量:局部变量在函数或代码块内部定义,它的作用域仅限于所在函数或代码块内。局部变量存储在栈区,它的生命周期从函数调用开始到结束,函数结束时局部变量的内存自动释放。
2. 指针和引用的区别
-
指针:指针是一个变量,用于存储另一个变量的内存地址。它可以是空指针(即
nullptr或NULL),并且指针可以重新指向不同的对象。指针使用符号*来进行解引用操作,从而访问或修改它所指向的内存地址中的数据。 -
引用:引用是一个变量的别名,必须在声明时进行初始化,且一旦绑定到某个对象之后,引用不能再改变绑定的对象。引用操作比指针更加简洁,避免了空引用的出现,因此比指针更安全,但没有指针的灵活性。
-
内存占用:指针通常占用独立的内存空间来存储地址,而引用只是对象的别名,不占用额外的内存。
3. C++内存区
C++ 程序的内存通常分为以下几个部分:
-
栈区(Stack):用于存储局部变量和函数调用信息(如函数的参数、返回地址、局部变量)。栈区内存由系统自动分配和释放,栈的内存使用是LIFO(后进先出)顺序的。
-
堆区(Heap):用于动态分配的内存,如通过
new或malloc分配的内存。堆内存的管理由程序员负责,必须显式释放。堆区的内存使用不遵循特定的顺序。 -
全局/静态区(Global/Static Data Segment):存储全局变量、静态变量和常量,程序从开始到结束一直保留这些变量的存储空间。
-
常量区(Constant Data Segment):存储常量数据,如字符串常量和
const修饰的变量。这部分数据通常在程序的整个生命周期内不可修改。 -
代码区(Text Segment):存储程序的可执行代码,内存分配由操作系统负责,通常是只读的。
4. static关键字和const关键字的作用
-
static:
- 修饰局部变量时,使变量具有静态存储期限,即该变量在函数多次调用之间保留其值,并且只初始化一次。
- 修饰全局变量时,使变量的作用域仅限于定义它的文件中,不能被其他文件访问。
- 修饰成员函数时,使该函数属于类而非对象,可以通过类名直接访问静态成员函数。
-
const:
- 用于定义常量,表示其值不能被修改。
- 修饰指针时可以限制指针所指对象或指针本身的可变性(如常量指针和指针常量)。
- 修饰成员函数时表示该函数不会修改类的成员变量。
5. 常量指针和指针常量之间有什么区别
-
常量指针(pointer to const):指针所指向的对象是常量,不能通过该指针修改对象的值,但可以修改指针本身的指向。例如:
1
const int* p; // p 是一个常量指针,不能修改 *p 的值
-
指针常量(const pointer):指针本身是常量,不能改变指向的对象,但可以修改该对象的值。例如:
1
int* const p; // p 是一个指针常量,不能改变 p 的指向,但可以修改 *p 的值
6. 结构体和类的区别
-
结构体(struct):默认访问权限为
public,结构体通常用于简单的数据封装,主要用于存储数据,而不包含复杂的行为(成员函数)。 -
类(class):默认访问权限为
private,类不仅用于数据封装,还用于封装行为(即成员函数),强调封装、继承和多态。类支持面向对象的各种特性,如访问控制、继承、多态等。
7. 什么是智能指针,C++有几种智能指针
-
智能指针(Smart Pointer):是一种对象,用于管理动态分配的内存,智能指针在其生命周期结束时自动释放所管理的内存,从而避免内存泄漏。
-
C++11 引入了三种智能指针:
unique_ptr:独占所有权,不能共享。适用于对象只有一个所有者的情况。shared_ptr:共享所有权,多个智能指针可以共享同一个对象。当最后一个shared_ptr被销毁时,管理的对象才会被释放。weak_ptr:弱引用,不会影响对象的生命周期,通常用于解决循环引用问题。
8. 智能指针的实现原理是什么
智能指针的实现原理依赖于RAII(Resource Acquisition Is Initialization)原则,通过智能指针的构造函数获取资源,通过析构函数释放资源。
shared_ptr的实现依赖于引用计数:每次复制shared_ptr,引用计数加一,每次销毁shared_ptr,引用计数减一,当引用计数变为零时,自动释放对象。unique_ptr利用移动语义实现独占所有权,当对象的所有权被转移时,原来的指针会被置为nullptr。
9. new和malloc有什么区别
-
new:
- 是运算符,分配内存的同时调用构造函数,进行对象初始化。
- 返回特定类型的指针,不需要类型转换。
- 可以被重载,提供更多灵活性。
-
malloc:
- 是库函数,只分配内存,不调用构造函数。
- 返回
void*类型指针,需要手动转换为具体类型。 - 无法直接管理类对象的构造与析构。
10. delete 和 free 有什么区别?
-
delete:
- 用于释放由
new分配的内存,同时调用对象的析构函数以清理资源。
- 用于释放由
-
free:
- 用于释放由
malloc分配的内存,不调用析构函数,因此不会清理对象内部资源,适用于C语言风格的内存分配。
- 用于释放由
11. 堆和栈的区别
-
栈(Stack):
- 存储局部变量和函数调用信息,由系统自动管理。
- 内存分配效率高,但空间有限。
- 内存使用是后进先出的顺序,通常用于小规模、短时间的存储。
-
堆(Heap):
- 存储动态分配的内存,内存管理由程序员负责。
- 内存空间大,但分配和释放较慢,容易产生碎片。
- 通常用于存储大规模、需要灵活分配的对象。
12. 什么是内存泄漏,如何检测和防止?
-
内存泄漏:指程序中动态分配的内存未被释放,导致这些内存无法再被访问和使用,进而浪费系统资源。
-
检测方法:
- 手动跟踪分配与释放的内存,使用工具如
valgrind或Visual Studio Memory Profiler。
- 手动跟踪分配与释放的内存,使用工具如
-
防止方法:
- 使用智能指针(如
unique_ptr、shared_ptr)自动管理内存。 - 编写良好的内存管理策略,确保每次动态分配的内存都有相应的释放操作。
- 使用智能指针(如
13. 什么是野指针?如何避免?
-
野指针:指向已释放或未初始化的内存的指针,访问野指针会导致程序的未定义行为,可能引发崩溃或数据损坏。
-
避免方法:
- 初始化指针为
nullptr。 - 在释放指针所指内存后将指针置为
nullptr。 - 尽量使用智能指针自动管理内存。
- 初始化指针为
14. C++面向对象三大特性
C++的面向对象编程包括以下三大特性:
-
封装:将数据和操作这些数据的函数封装在一个类中,通过限制数据访问(如使用
private和protected访问修饰符)来保护数据。类对外只暴露接口函数,通过接口访问内部数据和功能。 -
继承:允许一个类从另一个类派生,继承基类的属性和行为。派生类可以扩展或修改基类的功能,增强代码的复用性。C++ 支持单继承和多继承。
-
多态:基类的指针或引用可以指向派生类对象,且能够调用派生类的重写方法。多态通过虚函数实现,使得同一个接口可以有不同的行为表现,增强了程序的灵活性和可扩展性。
15. 简述一下C++的重载和重写,以及它们的区别和实现方式
-
重载(Overloading):是指在同一作用域中允许多个同名函数存在,但它们的参数列表(参数类型、个数或顺序)不同。编译器会根据调用时的参数来决定调用哪个函数。重载发生在同一类中,可以用于普通函数和运算符。
-
重写(Overriding):是指派生类重新定义基类的虚函数,函数名和参数列表都相同。重写是为了在继承体系中实现多态,基类指针或引用可以调用派生类重写的函数。重写只发生在派生类和基类之间。
区别:
- 重载发生在编译时,属于静态多态。
- 重写发生在运行时,属于动态多态。
实现方式:
- 重载:直接定义同名函数,但参数列表不同。
- 重写:基类中的函数必须标记为
virtual,在派生类中使用相同的函数签名,并通过override关键字确保重写。
16. C++怎么实现多态
多态通过虚函数(virtual function) 实现。基类中定义虚函数,派生类可以重写这些虚函数。使用基类指针或引用指向派生类对象时,调用的函数会根据对象的实际类型动态确定。
步骤:
- 在基类中声明虚函数。
- 在派生类中重写虚函数。
- 使用基类指针或引用调用派生类的重写函数,确保多态性。
17. 虚函数和纯虚函数的区别
-
虚函数:基类中使用
virtual关键字声明的函数,可以在派生类中被重写。基类可以提供虚函数的实现,也可以让派生类选择是否重写。 -
纯虚函数:基类中没有具体实现的虚函数,必须由派生类实现。纯虚函数的声明格式为:
1
virtual void func() = 0;
区别:
- 虚函数可以有实现,纯虚函数必须在派生类中实现。
- 包含纯虚函数的类称为抽象类,无法实例化。
18. 虚函数是怎么实现的
虚函数通过虚函数表(vtable) 来实现。每个包含虚函数的类都有一个指向虚函数表的指针,称为虚表指针(vptr)。虚函数表中存储的是该类的虚函数地址。当调用虚函数时,程序通过虚表指针找到虚函数表,并从中获取实际调用的函数地址。
19. 虚函数表是什么
虚函数表(vtable) 是一个存储类中虚函数地址的数组。每个包含虚函数的类都有一个虚函数表,派生类的虚表会覆盖基类的相应条目。通过基类指针调用虚函数时,程序在运行时根据对象的类型查找虚表,找到对应的虚函数地址并执行。
20. 什么是构造函数和析构函数?构造函数、析构函数可以是虚函数吗?
-
构造函数:用于在创建对象时初始化对象的成员变量。每个类都有一个构造函数,如果不显式定义,编译器会提供默认构造函数。
-
析构函数:在对象生命周期结束时被调用,主要用于释放资源和执行清理操作。析构函数名与类名相同,前面加
~符号。
虚函数:
-
析构函数可以是虚函数。这在多态场景中很重要,基类的析构函数需要标记为虚函数,以便通过基类指针删除派生类对象时,正确调用派生类的析构函数,防止资源泄漏。
-
构造函数不能是虚函数,因为在创建对象时必须明确调用哪个类的构造函数,虚表和虚函数的机制还未初始化。
21. C++构造函数有几种,分别什么作用
-
默认构造函数:无参数的构造函数,如果没有显式定义,编译器会自动生成。
-
参数化构造函数:带有参数的构造函数,用于根据给定的参数初始化对象。
-
拷贝构造函数:用于通过已有对象来初始化新对象,接受一个同类对象的引用作为参数。
-
移动构造函数(C++11 引入):用于通过转移资源来初始化对象,而不是复制数据,避免不必要的性能开销。
22. 深拷贝与浅拷贝的区别
-
浅拷贝:只复制对象的成员变量的值,若成员是指针,则仅复制指针的地址,不会复制指针指向的实际数据。这可能会导致多个对象共享同一块内存,产生潜在的内存管理问题。
-
深拷贝:不仅复制对象的成员变量,还复制指针指向的数据,确保每个对象都有独立的内存空间。深拷贝通常需要手动编写拷贝构造函数和赋值操作符。
23. STL 容器了解哪些
STL 提供了几种常见的容器类型:
- 顺序容器:
vector、deque、list、array等,适用于线性存储和访问。 - 关联容器:
map、set、multimap、multiset等,适用于基于键的有序访问。 - 无序容器:
unordered_map、unordered_set等,使用哈希表进行存储和查找。
24. vector和list的区别
-
vector:基于连续的内存存储,支持随机访问,插入或删除元素时可能需要移动其他元素,插入效率较低,但访问速度快。
-
list:基于双向链表存储,不支持随机访问,但插入或删除元素时只需调整指针,不影响其他元素,因此插入删除效率较高。
25. vector 底层原理和扩容过程
vector 使用连续的内存存储,当容量不够时会自动扩容。扩容时,vector 会分配一块新的更大的内存(通常是当前容量的 2 倍),然后将旧数据复制到新内存中,最后释放旧内存。
26. push_back()和emplace_back()的区别
push_back():将现有的对象拷贝或移动到容器的末尾。emplace_back():直接在容器末尾构造对象,避免了不必要的拷贝或移动操作,效率更高。
27. map、deque、list的实现原理
-
map:基于红黑树实现,提供有序的键值对存储和高效的查找、插入、删除操作,时间复杂度为 O(log n)。 -
deque:双端队列,支持在两端高效地插入和删除元素。其底层实现为一组动态数组块。 -
list:基于双向链表实现,每个元素都有前后指针,适合频繁的插入和删除操作。
28. map与unordered_map的区别和实现机制
-
map:基于红黑树实现,键值对按键的顺序存储,查找、插入和删除的时间复杂度为 O(log n)。 -
unordered_map:基于哈希表实现,键值对无序存储,查找、插入和删除的时间复杂度为 O(1)(理想情况下),但如果出现哈希冲突,性能可能下降。
29. C++11新特性有哪些
C++11 引入了大量新特性,以下是一些主要的改进:
-
右值引用和移动语义:通过右值引用(
&&)实现移动语义,避免不必要的拷贝操作,提升性能。 -
auto关键字:自动类型推导,简化代码书写。 -
nullptr:代替NULL表示空指针,消除了类型上的歧义。 -
constexpr:声明编译时常量,允许在编译期计算常量表达式,提高效率。 -
lambda 表达式:引入匿名函数,简化函数对象的使用。
-
智能指针:
std::shared_ptr、std::unique_ptr和std::weak_ptr用于自动管理动态分配的内存,避免内存泄漏。 -
std::thread:多线程支持,提供了创建和管理线程的标准方式。 -
std::tuple和std::array:增强了对数组和元组的支持。 -
新容器:如
unordered_map、unordered_set,提供基于哈希表的容器。 -
静态断言:
static_assert用于在编译时检查条件是否成立。 -
泛型编程增强:如
variadic templates(可变参数模板)允许编写接受任意数量参数的模板。
30. 移动语义有什么作用,原理是什么
作用:移动语义通过转移资源的所有权而不是复制资源,避免了不必要的内存分配和拷贝操作,显著提高了程序的性能。
原理:
-
在 C++ 中,右值引用(
&&)用于绑定右值对象,如临时对象或函数返回值。这些对象的生命周期即将结束,可以安全地将它们的资源转移到另一个对象中。 -
当对象可以利用移动语义时,移动构造函数或移动赋值操作符会通过转移资源所有权(如指针、文件句柄等)来避免深度拷贝,减少性能开销。
示例:
1 | class MyClass { |
31. 左值引用和右值引用的区别
-
左值引用(
T&):用于引用内存中有命名的持久对象,即左值。左值引用不能绑定到右值(临时对象),只能引用左值。 -
右值引用(
T&&):用于引用临时对象或右值,可以绑定到即将被销毁的临时对象,允许直接对右值进行修改或资源转移。
区别:
- 左值引用用于长期存在的对象,而右值引用用于短期临时对象的所有权转移或修改。
- 右值引用通常用于实现移动语义。
32. 说一下lambda函数
Lambda 函数是 C++11 引入的匿名函数,可以直接在函数体中定义简洁的函数对象,常用于标准库算法的回调函数中。
语法:
1 | [capture](parameters) -> return_type { function_body }; |
- capture:捕获外部变量的方式,可以是按值(
[=])或按引用([&])。 - parameters:传递给 Lambda 函数的参数。
- return_type(可选):函数返回值类型(通常编译器会自动推导)。
示例:
1 | auto add = [](int a, int b) -> int { return a + b; }; |
33. C++如何实现一个单例模式
单例模式保证一个类只有一个实例,并提供全局访问点。C++ 实现单例模式的方式包括:
- 懒汉模式:实例在第一次使用时创建。
- 饿汉模式:实例在程序启动时创建。
线程安全的懒汉模式实现示例:
1 |
|
34. 什么是菱形继承
菱形继承是指在多重继承中,一个派生类同时继承自两个基类,而这两个基类又继承自同一个祖先类,形成菱形结构。
问题:菱形继承会导致二义性问题,即祖先类的成员在派生类中存在两份。为了解决这个问题,C++ 引入了虚继承,通过 virtual 关键字让派生类共享一个基类的实例。
示例:
1 | class A { ... }; |
35. C++中的多线程同步机制
C++ 提供了多种多线程同步机制,以避免线程间的竞争条件,保证数据一致性:
-
互斥锁(
std::mutex):保护共享资源的访问,通过lock()和unlock()控制对资源的独占访问。 -
递归锁(
std::recursive_mutex):允许同一线程多次获得同一个锁。 -
条件变量(
std::condition_variable):用于线程间的同步,允许一个线程等待某个条件的满足,再继续执行。 -
读写锁(
std::shared_mutex):允许多个线程并发读取,但只有一个线程可以写入。
36. 如何在C++中创建和管理线程?
C++11 提供了标准库 std::thread 用于创建和管理线程,此外还提供了 std::async、std::future 等工具进行异步任务管理。
创建线程:
1 | void task() { |
-
std::thread:用于创建和运行新线程。线程可以通过函数指针、Lambda 函数、函数对象等方式启动。 -
join():阻塞当前线程,直到新线程完成。 -
detach():使线程在后台运行,当前线程不必等待其结束。
此外,C++11 还提供了 std::async 用于异步执行函数,并通过 std::future 获取异步任务的结果:
1 | auto future = std::async(std::launch::async, task); |